
Aprendizagem de Métricas¶
Aprendizagem de Métricas é um paradigma de aprendizado de máquina voltado para a construção de representações em que a noção de distância ou similaridade entre exemplos reflete relações semânticas relevantes. Em vez de simplesmente prever rótulos, o objetivo é treinar modelos capazes de projetar os dados em um espaço latente onde amostras semelhantes fiquem próximas e amostras diferentes fiquem afastadas. Essa abordagem é amplamente utilizada em tarefas como verificação de faces, recuperação de imagens e sistemas de recomendação, em que a comparação entre pares ou conjuntos de exemplos é mais importante do que a classificação tradicional. Métodos como redes siamesas e redes de tripletos são exemplos clássicos de arquiteturas aplicadas nesse contexto.
Siamese Networks¶
As Siamese Networks, introduzidas por Yann LeCun e seus colegas em 1993, são uma arquitetura poderosa que pode ser usada tanto em cenários supervisionados quanto em self-supervised learning. No contexto de self-supervision, as Siamese Networks são amplamente utilizadas em técnicas de aprendizado contrastivo, onde a rede aprende a comparar pares de dados. A arquitetura consiste em dois ou mais ramos idênticos (compartilhando pesos) que processam diferentes amostras e geram representações latentes, que são então comparadas para medir similaridade ou dissimilaridade. Em vez de rotular explicitamente cada amostra, o modelo é treinado para maximizar a similaridade entre amostras relacionadas (pares positivos) e minimizar a similaridade entre amostras diferentes (pares negativos). Essa abordagem de auto-supervisão tem sido fundamental para tarefas como detecção de similaridade, reconhecimento facial e até mesmo aprendizado de representações robustas sem a necessidade de rótulos complexos.
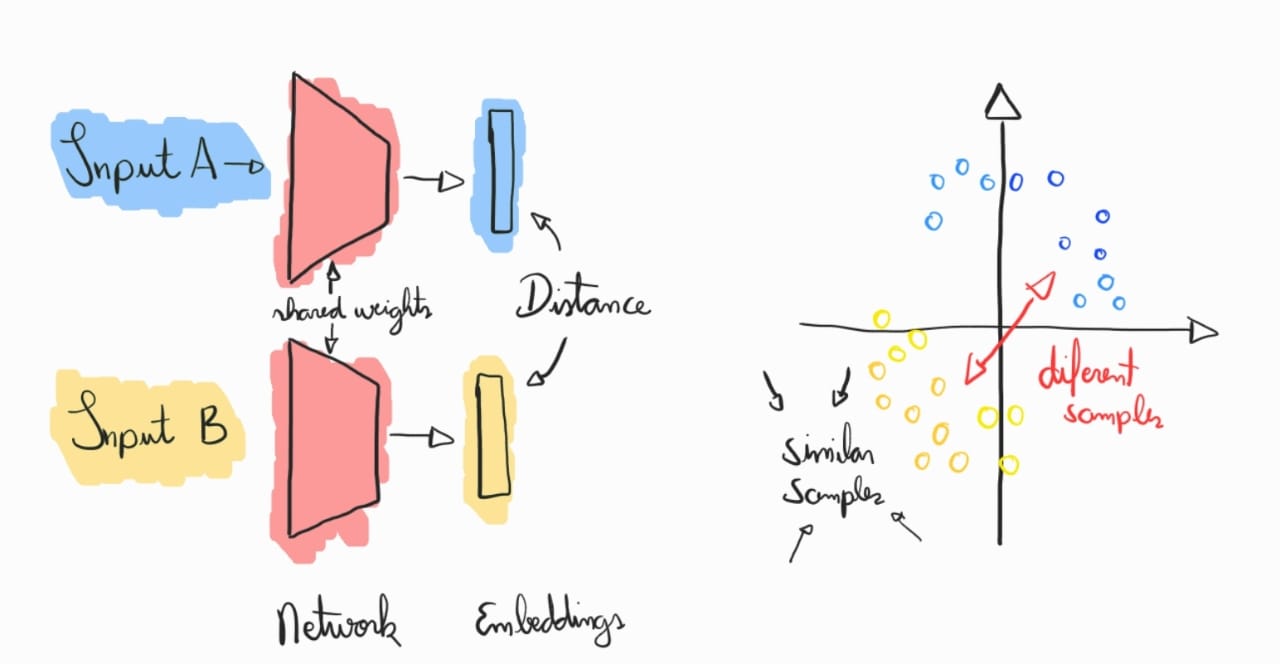
No artigo original sobre Siamese Networks para verificação de assinaturas, o treinamento envolvia o uso de uma rede neural com dois ramos idênticos (compartilhando pesos), que processavam duas entradas (duas assinaturas) para gerar representações latentes. A distância do cosseno () entre os espaços latentes ( e ) era utilizada para medir a similaridade entre essas representações. Durante o treinamento, pares de dados eram apresentados à rede, sendo pares positivos (assinaturas da mesma pessoa) e pares negativos (assinaturas falsas, ou de pessoas diferentes). O objetivo era minimizar a distância do cosseno para pares positivos, garantindo que as representações das assinaturas de uma mesma pessoa fossem semelhantes, e maximizar essa distância para pares negativos, de modo que assinaturas de pessoas diferentes fossem distinguidas claramente. Esse processo permitia à rede aprender a medir a similaridade entre assinaturas com base na orientação dos vetores no espaço latente, sem depender da magnitude dos vetores.
Siamese Networks Modernas¶
As redes siamesas modernas são geralmente treinadas utilizando uma função de perda baseada na contrastive loss ou na triplet loss, com o objetivo de aprender representações latentes discriminativas. Durante o treinamento com contrastive loss (), a rede recebe pares de exemplos, que podem ser pares positivos (amostras da mesma classe, ) ou pares negativos (amostras de classes diferentes, ). Para os pares positivos, a rede é treinada para minimizar a distância entre as representações latentes geradas pelos dois ramos da rede, garantindo que amostras semelhantes sejam mapeadas para pontos próximos no espaço latente. Para os pares negativos, a rede é treinada para maximizar a distância, separando representações de amostras diferentes por uma margem mínima.
Além da contrastive loss, a triplet loss tem se tornado popular, utilizando conjuntos de três exemplos — uma âncora (), um positivo (mesma classe, ) e um negativo (classe diferente, ) — para otimizar simultaneamente a proximidade entre o âncora e o positivo e a separação do âncora em relação ao negativo por uma margem . Esses métodos têm sido amplamente aplicados em tarefas de verificação e reconhecimento facial, detecção de similaridades e aprendizado de representações robustas e comparáveis.
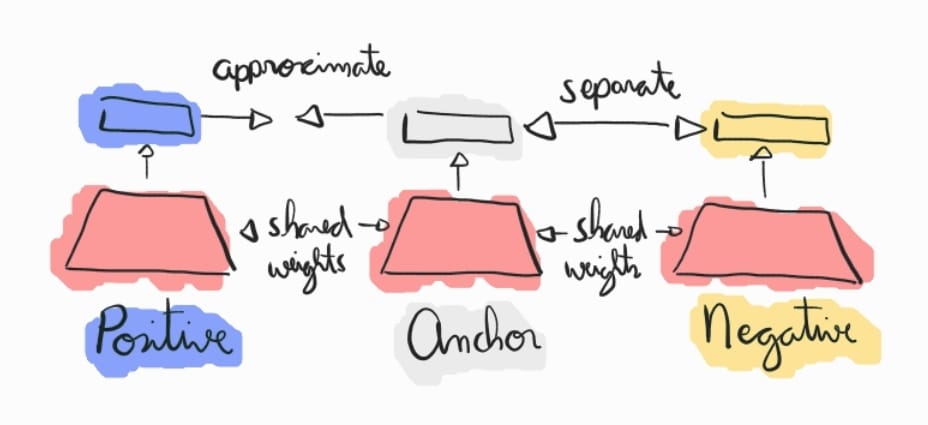
A triplet loss pode ser mais eficaz em cenários onde as classes são complexas ou têm fronteiras mais difíceis de distinguir. A inclusão de exemplos negativos diretamente no cálculo da perda garante que o modelo seja treinado para maximizar a separação entre diferentes classes, enquanto a contrastive loss pode, em alguns casos, não explorar bem essas relações entre classes. A contrastive loss apenas otimiza dois pontos de cada vez, enquanto a triplet loss garante uma estrutura relativa no espaço latente. Além disso, a triplet loss é projetada para lidar com hard negatives — exemplos negativos que são muito semelhantes à âncora, mas pertencem a uma classe diferente. Esses exemplos são críticos para o aprendizado eficaz de representações discriminativas. A triplet loss garante que esses exemplos sejam usados de forma eficiente no treinamento, enquanto a contrastive loss trata todos os pares negativos da mesma forma, sem distinção entre hard e easy negatives.
Considerações Finais¶
Neste capítulo, abordamos um paradigma diferente para treino de redes neurais artificiais. Ao invés de utilizar dados anotados, utilizamos os próprios dados de diversas formas diferentes para realizar o que chamamos de treino auto-supervisionado.
Próximo Capítulo¶
No próximo capítulo, abordaremos aprendizagem auto-supervisionada, envolvendo modelos como Autoencoders e métodos de Contrastive Learning.
Referências¶
Bromley, J., Guyon, I., LeCun, Y., Säckinger, E., & Shah, R. (1993). Signature verification using a" siamese" time delay neural network. Advances in neural information processing systems, 6.