
Receita para Treinar Redes Neurais Artificiais¶
Andrej Karpathy, em seu famoso post “A Recipe for Training Neural Networks”, compartilha uma abordagem prática e eficiente para treinar redes neurais artificiais. Ele destaca que o sucesso no treinamento depende de uma combinação cuidadosa de boas práticas. A receita inclui começar com arquiteturas simples e testar rapidamente a performance do modelo antes de complicá-lo. Ele recomenda ajustar o aprendizado de maneira incremental, focando em entender o comportamento do modelo com overfitting e underfitting. Entre as dicas valiosas, Karpathy enfatiza o uso de visualizações para compreender o comportamento da rede, a importância de usar lotes de dados adequados, e a prática de sempre monitorar as métricas de performance.
Análise Exploratória de Dados¶
A análise exploratória de dados (EDA) é uma etapa fundamental no desenvolvimento de modelos de machine learning, conforme destacado no tópico “Become One with the Data”, de Andrej Karpathy. O objetivo da EDA é obter uma compreensão profunda dos dados antes de construir qualquer modelo. Isso inclui a visualização de distribuições, detecção de outliers, análise de correlações e identificação de padrões ou anomalias que possam afetar o desempenho do modelo. Karpathy enfatiza que passar tempo com os dados, analisando suas características e peculiaridades, é crucial para tomar decisões informadas sobre pré-processamento, engenharia de features e seleção de algoritmos. Em resumo, a EDA permite que o pesquisador se familiarize com o comportamento dos dados, maximizando as chances de sucesso do modelo final.
Criar uma Arquitetura Inicial¶
Ao criar uma arquitetura inicial para redes neurais, é importante adotar uma abordagem estruturada que facilite o processo de treinamento e depuração. O uso de boas práticas, desde a escolha de padrões arquiteturais até a normalização dos dados, ajuda a garantir que o modelo aprenda de maneira eficaz. Além disso, a realização de testes em conjuntos de dados reduzidos pode fornecer uma visão clara de como o modelo está se comportando e ajudar na identificação precoce de falhas.
Iniciar com padrões (arquiteturas e otimizadores): Utilize arquiteturas consagradas como MLPs ou CNNs, e otimizadores como Adam ou SGD, que são confiáveis e amplamente utilizados.
Normalizar dados: Assegure-se de que os dados estejam normalizados, garantindo que as variáveis de entrada estejam em escalas semelhantes, facilitando o aprendizado.
Uso de conjuntos reduzidos (para overfit): Teste o modelo em um conjunto de dados pequeno para verificar se ele consegue overfit. Isso ajuda a garantir que o modelo e a função de perda estão funcionando corretamente.
Diagnóstico de falhas no treino: Se o modelo não consegue overfit em um conjunto pequeno, pode haver problemas na arquitetura, nos hiperparâmetros ou na implementação, e isso requer uma investigação mais detalhada.
Avaliar Modelo¶
A avaliação de modelo é uma etapa crucial no desenvolvimento de redes neurais, pois permite verificar se o modelo está aprendendo adequadamente e se generaliza bem para novos dados. Além de medir a acurácia ou outras métricas de desempenho, a análise detalhada dos erros cometidos pelo modelo é fundamental para identificar áreas de melhoria e ajustar os hiperparâmetros ou a arquitetura. As curvas de aprendizagem também são ferramentas valiosas, pois mostram como o desempenho do modelo evolui ao longo do tempo durante o treinamento e ajudam a detectar problemas como overfitting ou underfitting.
Aqui estão alguns itens importantes para a análise de erros e curvas de aprendizagem:
Identificar erros sistemáticos: Verifique se o modelo está cometendo erros semelhantes em determinados tipos de exemplos. Isso pode indicar a necessidade de melhorar a representação dos dados ou ajustar o pré-processamento.
Comparar performance de treino e validação: Analisar a diferença entre as curvas de erro no conjunto de treino e no de validação ajuda a identificar overfitting (quando o erro de validação é muito maior que o de treino) ou underfitting (quando ambos os erros são altos).
Monitorar a convergência: Acompanhe as curvas de aprendizado para garantir que o modelo está convergindo corretamente. Caso a perda não esteja diminuindo, pode ser necessário ajustar a taxa de aprendizado ou rever a arquitetura.
Ajustar com base nos erros: Use os insights dos erros para ajustar a arquitetura, os hiperparâmetros ou até o pré-processamento dos dados, sempre com o objetivo de melhorar o desempenho do modelo.
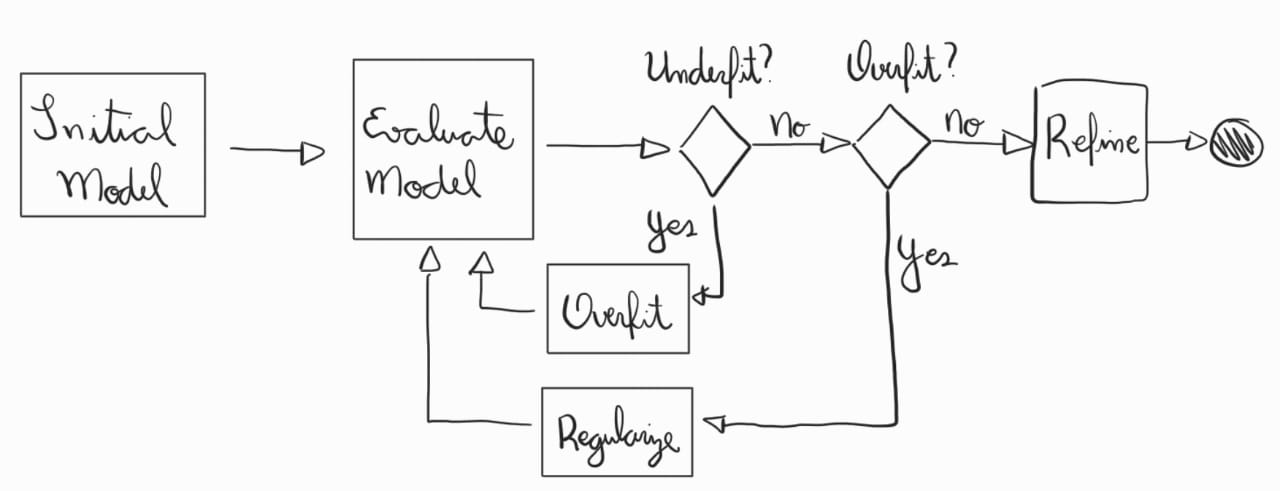
Overfit¶
Garantir que o modelo consiga overfit no conjunto de treino é uma etapa crítica para verificar se ele tem a capacidade de aprender os padrões, mesmo que de forma exagerada. Para isso, algumas abordagens podem ser seguidas, como simplificar o problema e ajustar os parâmetros da rede. Caso o modelo não consiga overfit, pode haver problemas na arquitetura ou na implementação.
Abaixo temos um gráfico padrão representando underfitting, onde o erro do modelo é muito alto no conjunto de treino.
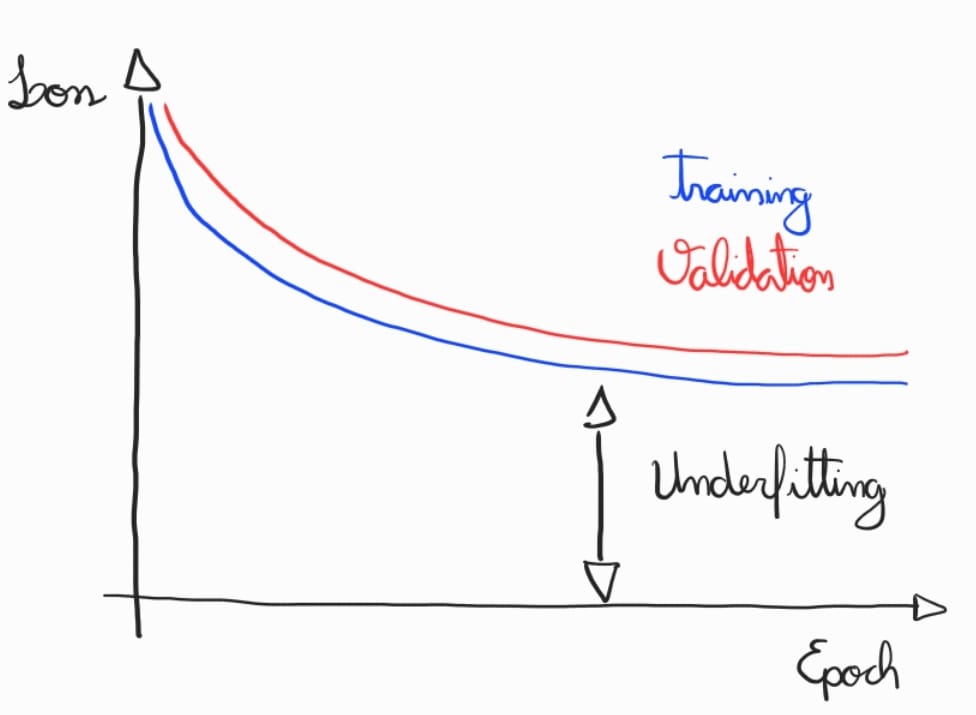
Aqui estão alguns pontos importantes a serem observados para melhorar esta situação:
Aumentar a capacidade do modelo: Adicione mais neurônios ou camadas à rede para garantir que ela tenha capacidade suficiente para aprender.
Reduzir regularização: Desative técnicas como dropout e weight decay, que impedem o overfitting, para facilitar a memorização.
Testar a função de perda: Certifique-se de que a função de perda está bem configurada e que o modelo consegue otimizar seu valor no conjunto de treino.
Temos abaixo outra situação, comumente relacionada a taxa de aprendizados muito altos para o problema.
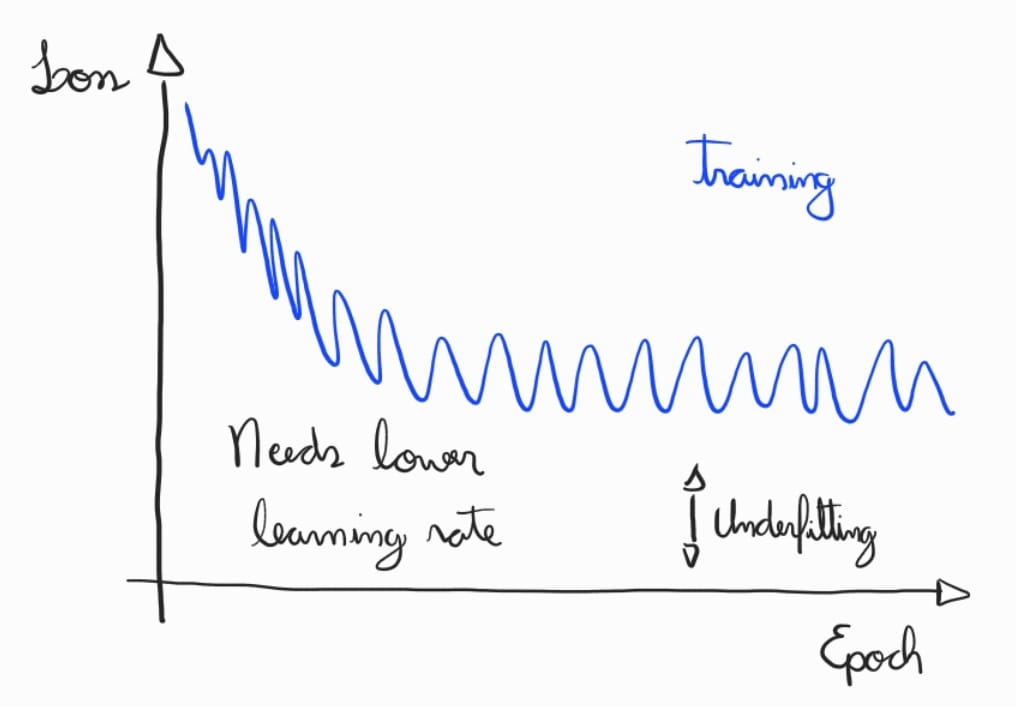
Para esta situação, deve-se:
Ajustar a taxa de aprendizado: Verifique se a taxa de aprendizado está adequada, já que uma taxa muito alta pode impedir o modelo de aprender corretamente.
Finalmente, temos abaixo outra situação onde ocorre underfitting. Porém, para tal situação, pode-se continuar o treinamento ou acelerar o processo com taxas de aprendizados maiores.
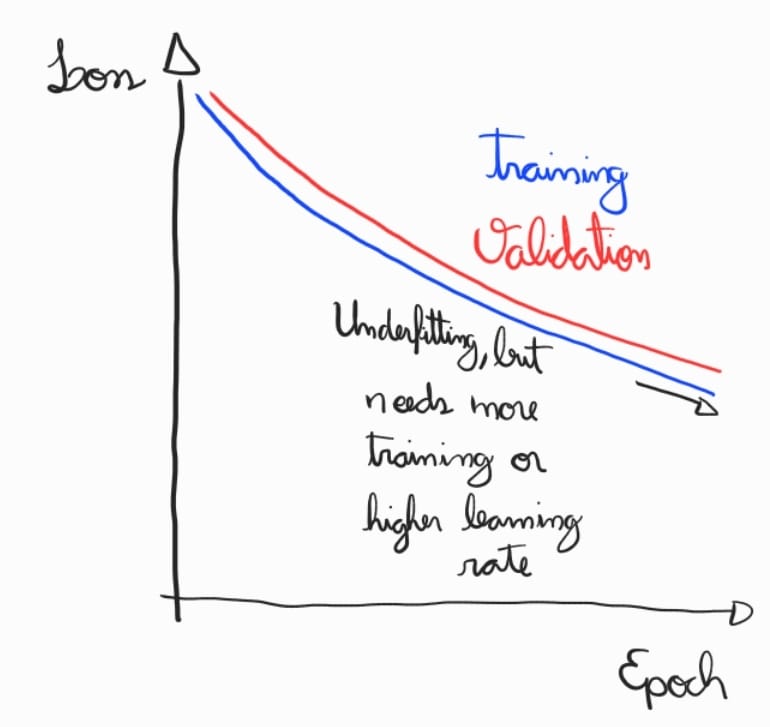
Regularização¶
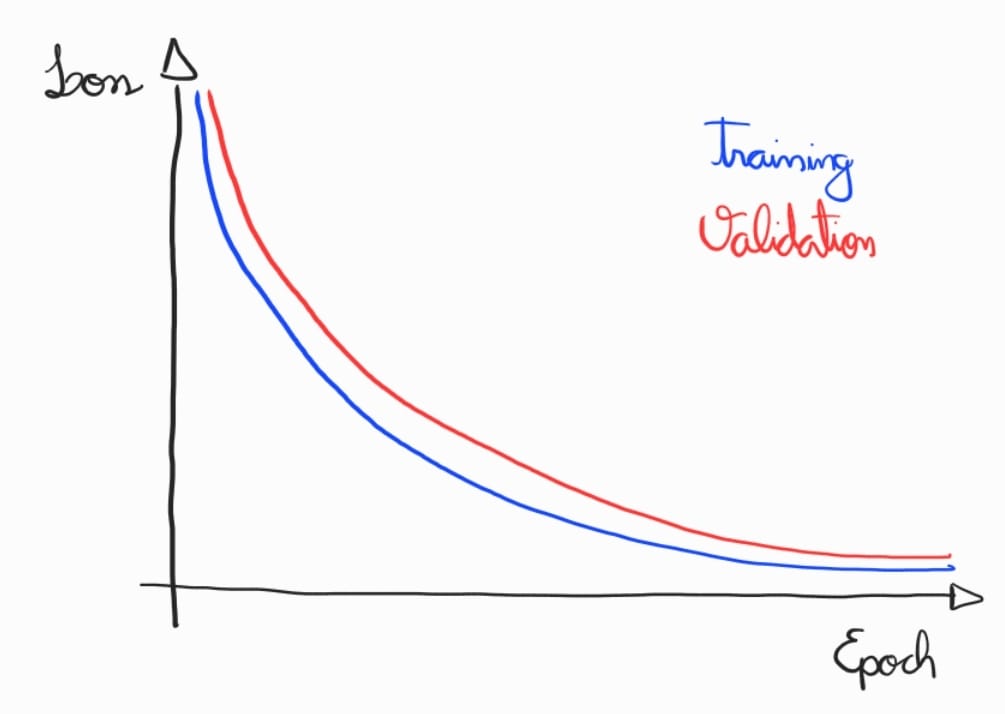
Após conseguir uma perda baixa no conjunto de treino, deve-se realizar a regularização. A regularização é fundamental para evitar que o modelo overfit aos dados de treino, permitindo uma melhor generalização para dados novos. A curva de aprendizado ótima deve-se chegar a baixos valores no conjunto de treino e validação, conforme abaixo.
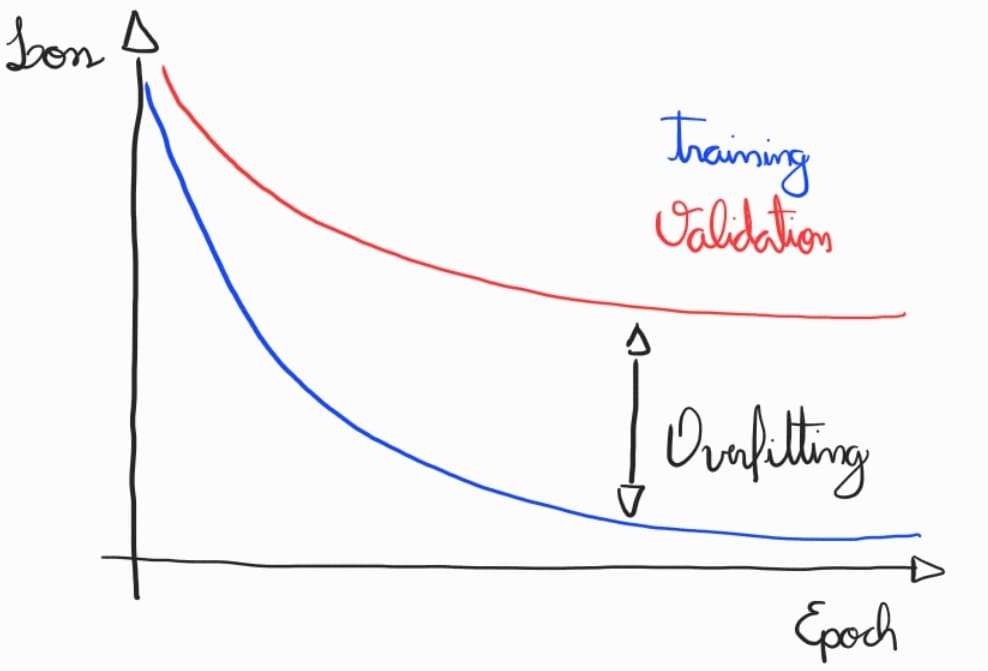
Porém, quando terminarmos a etapa de overfitting, geralmente estamos com uma curva de aprendizagem similar às que temos abaixo, com valores baixos no conjunto de treino e altos no conjunto de validação.
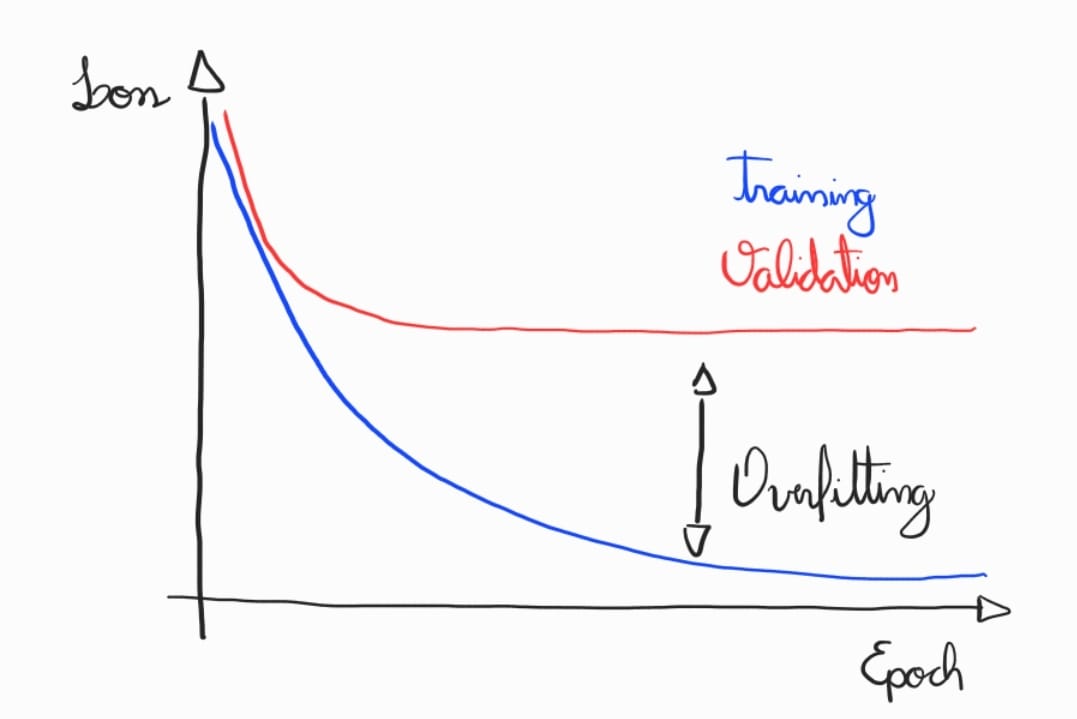
Existem diversas técnicas que podem ser aplicadas em diferentes etapas do treinamento para alcançar este resultado. A seguir, uma ordem recomendada de abordagens para regularização:
Adicionar mais dados: A maneira mais eficaz de melhorar a generalização é aumentar o tamanho do conjunto de dados com mais exemplos reais, sempre que possível.
Data augmentation: Se não for possível coletar mais dados, utilize técnicas de aumento de dados, como rotações, escalas ou distorções, para criar variações nos exemplos de treino.
Normalização de representações: Use batch normalization ou layer normalization para estabilizar o aprendizado, acelerar a convergência e melhorar a generalização do modelo.
Redução do batch size: Diminuir o tamanho do batch pode introduzir mais ruído no treinamento, ajudando o modelo a escapar de mínimos locais e generalizar melhor.
Dropout e regularização de parâmetros: Aplique dropout ou técnicas de regularização como weight decay para evitar que o modelo dependa muito de combinações específicas de parâmetros.
Label smoothing: Use label smoothing para suavizar as probabilidades de saída, reduzindo a confiança excessiva do modelo nas previsões e melhorando a generalização.
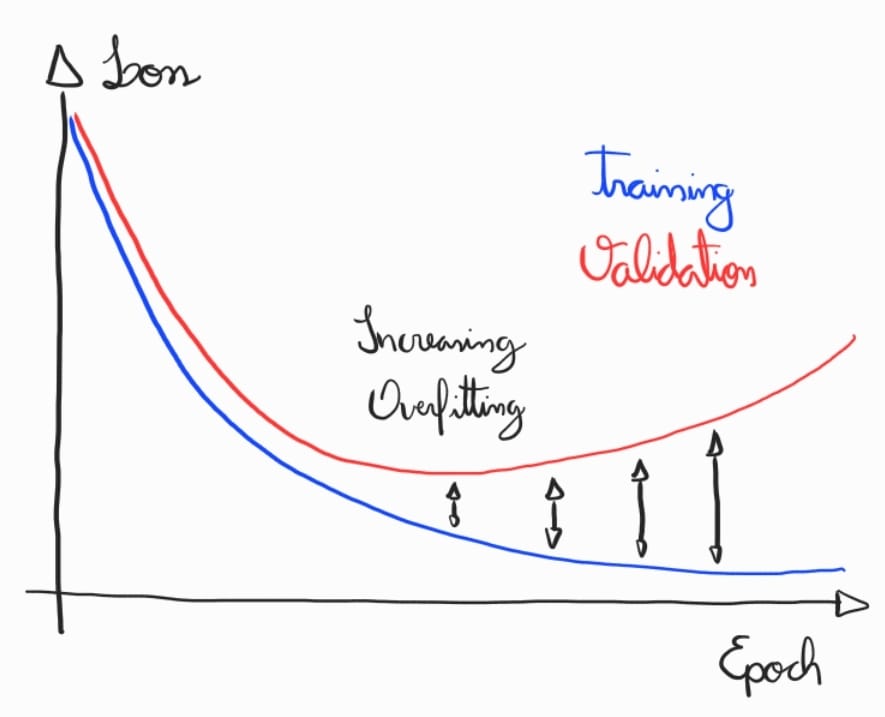
Early stopping: Monitore o erro de validação e pare o treinamento antes que o modelo comece a overfit, quando o erro de validação aumenta enquanto o erro de treino diminui.
Modificação de tamanho de modelo: Se o overfitting persistir, considere reduzir o número de neurônios ou camadas da rede para evitar que o modelo tenha capacidade excessiva de memorização.
Refinar¶
O refinamento de redes neurais é um processo contínuo de ajuste fino que busca otimizar o desempenho do modelo após a fase inicial de treinamento. Isso envolve ajustes precisos dos hiperparâmetros e o uso de técnicas avançadas para melhorar a estabilidade e a convergência do modelo. Refinar redes neurais é essencial para alcançar um bom equilíbrio entre desempenho e eficiência, garantindo que o modelo atinja seu potencial máximo em termos de precisão e generalização.
Aqui estão algumas abordagens para o refinamento:
Ajuste de hiperparâmetros: Experimente diferentes valores para hiperparâmetros importantes, como taxa de aprendizado, tamanho do batch, número de camadas e unidades por camada, para encontrar a combinação que melhora o desempenho do modelo.
Schedule de learning rate: Use um learning rate schedule que diminua a taxa de aprendizado ao longo do tempo. Técnicas como step decay ou cosine annealing ajudam a estabilizar o treinamento e encontrar um mínimo mais preciso.
Exponential Moving Average (EMA): Mantenha uma média exponencial dos pesos do modelo durante o treinamento. Essa técnica ajuda a suavizar as atualizações e pode melhorar a robustez do modelo, especialmente quando usado em conjunto com learning rate schedules.