![]()
Redes Neurais Convolucionais#
As redes neurais convolucionais (CNNs) surgiram como uma evolução natural das redes neurais perceptron multicamadas (MLPs) para lidar com dados estruturados em forma de grade, como imagens. Enquanto as MLPs conectam todos os neurônios de uma camada à seguinte, as CNNs exploram propriedades espaciais, aplicando filtros locais (convoluções) que capturam padrões como bordas, texturas e formas. Isso reduz drasticamente o número de parâmetros em comparação com MLPs para entradas de alta dimensão, além de introduzir indutivas de localidade e invariância translacional, tornando-as mais adequadas para visão computacional.
A arquitetura básica de uma CNN combina três blocos principais: camadas convolucionais (responsáveis por extrair características locais), camadas de pooling (que reduzem a dimensionalidade e aumentam a robustez a pequenas variações) e camadas totalmente conectadas no final (responsáveis pela decisão ou regressão, semelhante às MLPs). Esse desenho hierárquico permite que a rede aprenda representações de baixo nível até conceitos de alto nível. Assim, CNNs superaram MLPs em tarefas como reconhecimento de imagens, tornando-se o paradigma dominante em visão computacional até o surgimento de arquiteturas baseadas em attention, como Transformers.
Limitações da MLP#
A MLP é uma arquitetura versátil que, de acordo com o teorema de aproximação universal (Hornik et al, 1989), pode aprender qualquer função. Apesar disso, podem ser necessários muitos neurônios e, consequentemente, muitos parâmetros. Neste caso, em tarefas muito complexas e com muitos parâmetros, torna-se necessário ter à disposição muitos dados (Alwosheel et al, 2018), o que geralmente não é possível.
Em tarefas como visão computacional ou análise de sinais, podemos ter centenas a milhares de atributos de entrada (pixels/amostras) que, quando conectadas com camadas ocultas com centenas a milhares de neurônios, geram milhares a milhões de parâmetros que devem ser aprendidos. Nestes casos, seriam necessárias ainda mais amostras (em torno de 10 a 50 vezes o número de parâmetros).

Apesar disso, além de termos alta dimensionalidade em tais problemas, existe também uma estrutura espacial ou temporal que a MLP não explora de forma eficiente, pois trata cada entrada como independente. Nesse contexto, surgem as redes neurais convolucionais (CNNs), que utilizam filtros locais aplicados sobre regiões da entrada para extrair características relevantes, reduzindo o número de parâmetros e explorando a correlação entre vizinhos. Essa abordagem permite capturar bordas, texturas e padrões repetitivos de maneira hierárquica, tornando as CNNs especialmente adequadas para problemas de visão computacional e análise de sinais.
Camada de Convolução#
A operação de convolução resolve esse problema ao substituir a conexão densa da MLP por kernels (ou filtros) de tamanho reduzido, que percorrem a imagem aplicando o mesmo conjunto de pesos em diferentes regiões. Em vez de aprender um peso para cada pixel em relação a cada neurônio, o kernel aprende um pequeno conjunto de parâmetros compartilhados, capaz de detectar padrões locais como bordas horizontais, verticais ou texturas. Esse mecanismo reduz drasticamente o número de parâmetros e garante que uma mesma característica possa ser reconhecida em qualquer posição da imagem.

Visualmente, o kernel pode ser entendido como um “perceptron local” que analisa apenas uma vizinhança da entrada, e cuja aplicação repetida sobre toda a imagem permite compor representações cada vez mais complexas.

A convolução introduz dois conceitos fundamentais: compartilhamento de pesos e invariância translacional. Como o mesmo kernel é aplicado em toda a extensão da imagem, a rede não precisa aprender separadamente o mesmo padrão em diferentes posições, o que reduz ainda mais a quantidade de parâmetros e aumenta a capacidade de generalização. Além disso, uma característica detectada em um ponto (como uma borda ou textura) poderá ser reconhecida em qualquer outra região da imagem. Dessa forma, a convolução estabelece a base para a extração de features robustas e reutilizáveis, preparando o terreno para a sequência natural de operações em CNNs: funções de ativação, pooling e, por fim, camadas densas para a decisão final.
Funções de Ativação#
Após a convolução, aplica-se uma função de ativação não linear para permitir que a rede aprenda representações complexas. Nas CNNs, a mais utilizada é a ReLU (Rectified Linear Unit), que é simples, eficiente e reduz o problema do gradiente desaparecendo. Uma variação é a Leaky ReLU, que mantém um pequeno valor negativo para entradas menores que zero, evitando o problema dos neurônios “mortos” que nunca ativam. Mais recentemente, a GeLU (Gaussian Error Linear Unit) tem sido usada em arquiteturas avançadas, pois suaviza a transição entre valores negativos e positivos com base em uma função probabilística, oferecendo melhor desempenho em alguns cenários, especialmente em modelos de larga escala.
ReLU#
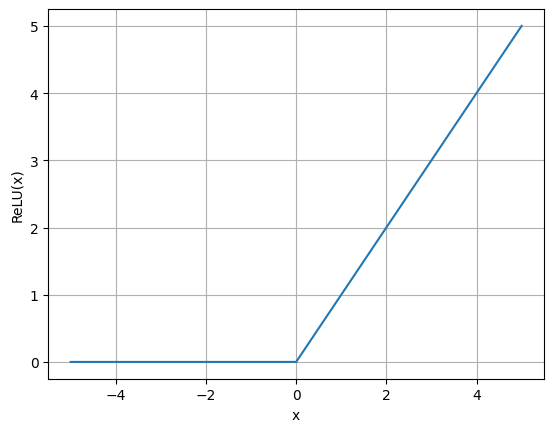
A função de ativação ReLU (Naim & Hinton, 2010), popularizada com a AlexNet (Krizhevsky et al, 2012), é uma das mais utilizadas em redes neurais modernas devido à sua simplicidade e eficácia. Sua fórmula é \(f(x)=\text{max}(0,x)\) , o que significa que ela transforma valores negativos em zero, enquanto mantém valores positivos inalterados. Isso introduz não-linearidade na rede, permitindo que ela aprenda padrões complexos. Comparada a funções de ativação anteriores, como sigmoid e tanh, a ReLU tem a vantagem de ser computacionalmente mais eficiente e de mitigar o problema do desvanecimento do gradiente, uma vez que seus gradientes são constantes para entradas positivas. No entanto, ReLU também pode sofrer com o problema de “neurônios mortos” quando muitas unidades se tornam zero, o que pode ser tratado com variantes como Leaky ReLU e GeLU (gaussian error linear unit).
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 101)
y = np.array([max(i, 0) for i in x])
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('ReLU(x)')
plt.grid()
plt.show()
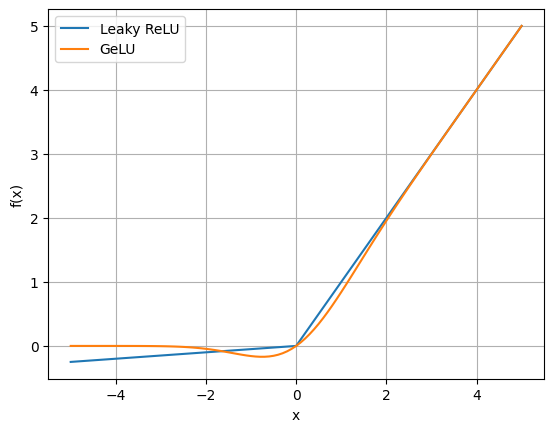
Variantes (Leaky ReLU e GeLU)#
Para diminuir problemas de neurônios mortos, variantes como Leaky ReLU e GeLU possuem valores diferentes de zero quando X é negativo. Leaky Relu, utilizando um certo valor \(\alpha\), possui o formato \(f(x,\alpha)=\text{max}(\alpha.x,x)\), enquanto GeLU pesa a entrada pelo quanto ela é provável de ser positiva sob uma distribuição normal padrão.
from scipy.special import erf
x = np.linspace(-5, 5, 101)
lrelu = np.array([max(i, 0.05*i) for i in x])
gelu = 0.5 * x * (1 + erf(x / np.sqrt(2)))
plt.plot(x, lrelu)
plt.plot(x, gelu)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.grid()
plt.legend(['Leaky ReLU', 'GeLU'])
plt.show()
Camada de Pooling#
A camada de pooling é utilizada para reduzir a dimensionalidade espacial das representações sem perder informações essenciais. Ela aplica uma operação de agregação em regiões locais da saída da convolução, sendo as mais comuns o max pooling (que seleciona o valor máximo) e o average pooling (que calcula a média). Esse processo traz dois benefícios principais: diminui o número de parâmetros e cálculos nas camadas seguintes e aumenta a robustez da rede a pequenas variações na entrada, já que detalhes locais são resumidos em características mais estáveis.

Camadas de Normalização#
Camadas de normalização surgiram para estabilizar e acelerar o treinamento de redes profundas. Nas primeiras CNNs, era comum o uso de Local Response Normalization (LRN), que normalizava a ativação de um neurônio considerando seus vizinhos próximos, inspirada em mecanismos biológicos de inibição lateral. Mais tarde, a técnica de Batch Normalization (BatchNorm) se tornou dominante, pois normaliza as ativações de cada camada em um mini-batch, reduzindo o internal covariate shift e permitindo taxas de aprendizado maiores e convergência mais estável.
Local Response Normalization#
A Local Response Normalization (LRN) é uma técnica de normalização usada em redes neurais convolucionais, introduzida pela primeira vez na AlexNet (Krizhevsky et al, 2012). Inspirada pela inibição lateral em neurônios biológicos, a LRN normaliza a ativação de um neurônio considerando a resposta de seus neurônios vizinhos dentro de uma pequena região. Isso ajuda a destacar ativações mais fortes e suprimir as mais fracas, promovendo uma competição entre neurônios e melhorando a generalização da rede. Embora tenha sido popular em arquiteturas antigas, como AlexNet e GoogLeNet, o LRN foi substituído por métodos mais modernos, como o Batch Normalization

Batch Normalization#
Batch Normalization (BN), introduzido por Ioffe e Szegedy em 2015, é uma técnica que normaliza as ativações de uma camada neural para cada mini-lote durante o treinamento. O principal objetivo do Batch Normalization é mitigar o problema do deslocamento interno da covariância, que ocorre quando as distribuições das ativações mudam de forma significativa entre as camadas durante o treinamento, dificultando a convergência. Ao normalizar as ativações de cada mini-lote com base na média e na variância, o BN estabiliza e acelera o treinamento, permitindo o uso de taxas de aprendizado maiores. Além disso, o BN atua como uma forma de regularização, reduzindo a necessidade de técnicas como o Dropout, e facilita o treinamento de redes neurais mais profundas. Essa técnica foi amplamente adotada em arquiteturas modernas, como a ResNet, e se tornou um componente padrão na maioria das redes neurais convolucionais.

Outras camadas de Normalização#
Além da BatchNorm, outras normalizações foram propostas para lidar com diferentes cenários. A Layer Normalization (LayerNorm) atua normalizando todas as ativações de uma amostra em uma camada, de forma independente do tamanho do batch, sendo amplamente usada em arquiteturas baseadas em transformers. Já a Instance Normalization (InstanceNorm) normaliza cada canal de cada amostra separadamente, sem considerar estatísticas do batch, o que a tornou popular em aplicações de visão computacional como style transfer. Por fim, a Group Normalization (GroupNorm) divide os canais em grupos e normaliza dentro de cada grupo, funcionando bem mesmo com batches muito pequenos, o que a torna útil em tarefas de visão de alta resolução em que limitações de memória restringem o tamanho do batch.
Camadas Densas (ou Completamente Conectadas)#
Por fim, após as etapas de convolução, ativação, pooling e normalização, as CNNs geralmente utilizam camadas densas para realizar a decisão final. Essas camadas funcionam de forma idêntica às que já vimos na MLP: todos os neurônios são conectados a todas as entradas, permitindo combinar as características extraídas anteriormente em uma representação de alto nível. Assim, enquanto as camadas convolucionais atuam como extratoras de features, as camadas densas cumprem o papel de classificador ou regressor, dependendo da tarefa.
Decisões de Projeto de Redes Neurais Convolucionais#
Em redes convolucionais, as escolhas arquiteturais determinam a capacidade do modelo de extrair padrões em diferentes escalas e níveis de abstração. A profundidade (número de camadas) aumenta a hierarquia de representações, enquanto a largura (número de filtros por camada) define a diversidade de características extraídas. O tamanho do kernel controla o campo receptivo local — kernels maiores capturam padrões mais amplos, enquanto menores focam em detalhes finos. O stride (passo) ajusta o quanto o filtro se desloca sobre a entrada, influenciando a redução de dimensionalidade e a sobreposição das regiões analisadas. Outras decisões, como padding ou uso de camadas de pooling, também afetam a resolução espacial e o equilíbrio entre custo computacional e riqueza das representações.
Profundidade e Largura#
Em redes convolucionais, profundidade refere-se ao número de camadas sucessivas (convolucionais ou blocos) e está ligada à capacidade do modelo de aprender representações progressivamente mais abstratas: redes mais profundas capturam padrões de alto nível a partir de combinações de características mais simples. Já a largura diz respeito ao número de filtros (ou canais de saída) em cada camada, controlando quanta variedade de padrões diferentes pode ser extraída em um mesmo nível de processamento. O aumento de profundidade tende a melhorar a hierarquia das representações, enquanto o aumento de largura amplia a diversidade de características aprendidas — ambos impactando diretamente a capacidade do modelo, custo computacional e risco de sobreajuste (overfitting).
Parâmetros da Convolução: Tamanho de Kernel, Stride e Padding#
O tamanho do kernel em uma camada convolucional determina a área local da entrada que cada filtro observa ao extrair características. Kernels pequenos (como 3×3) capturam padrões locais finos e são comuns em arquiteturas modernas por permitirem composições profundas com menos parâmetros, enquanto kernels maiores (como 5×5 ou 7×7) já cobrem regiões mais amplas e capturam padrões de contexto mais extenso em uma única operação. Esse tamanho, junto com stride, padding e o número de camadas, define o campo receptivo efetivo do modelo — ou seja, a região da entrada que influencia cada neurônio nas camadas posteriores. Ajustar o tamanho do kernel e o campo receptivo é essencial para equilibrar resolução espacial, custo computacional e capacidade de capturar dependências de longo alcance.

O passo (ou stride) controla de quantos pixels o filtro se desloca sobre a entrada a cada operação de convolução. Passos menores (como 1) mantêm maior sobreposição entre janelas consecutivas, preservando mais detalhes espaciais, mas aumentam o custo computacional. Passos maiores (como 2) reduzem a dimensionalidade mais rapidamente, atuando de forma semelhante a um downsampling inicial, porém com perda de resolução espacial. Ajustar o stride permite equilibrar granularidade das características extraídas e eficiência da rede.

O padding define como lidar com as bordas da entrada antes da convolução, adicionando valores artificiais (geralmente zeros) ao redor do mapa de entrada. O padding “válido” (sem adicionar bordas) reduz gradualmente as dimensões, enquanto o padding “mesmo” (same padding) preserva as dimensões originais da entrada após a convolução. Essa escolha afeta tanto o campo receptivo quanto a capacidade do modelo de processar informações nas bordas, influenciando diretamente o tamanho dos mapas de ativação e a profundidade possível da rede sem encolher demais a representação.

Kernels Especiais: Dilatação, Assimetria e Convolução 1x1#
A dilatação (dilation ou atrous convolution) controla o espaçamento entre os elementos do kernel, inserindo “buracos” entre os pesos do filtro. Isso aumenta o campo receptivo da convolução sem aumentar o número de parâmetros ou perder resolução espacial por downsampling. Com dilatações maiores, a rede consegue capturar dependências de longo alcance em uma única camada, enquanto dilatações menores se comportam como convoluções tradicionais. Essa técnica é muito usada em tarefas que exigem preservação de resolução e contexto amplo, como segmentação semântica ou detecção de padrões em sinais.
Além das convoluções de múltiplas escalas, um avanço significativo que surgiu em versões posteriores, como na Inception v2 e Inception v3 (Szegedy et al, 2014), foi o uso de convoluções assimétricas, como as convoluções 3x1 e 1x3. Essas convoluções assimétricas foram introduzidas para melhorar ainda mais a eficiência da rede. Ao decompor uma convolução regular de 3x3 em duas operações menores, como uma convolução 3x1 (captura de características na dimensão horizontal) e uma 1x3 (captura de características na dimensão vertical), a rede pode manter o mesmo campo receptivo de uma convolução 3x3, porém com menos parâmetros e menor custo computacional. Essa técnica ajuda a rede a capturar padrões em direções específicas de forma mais eficiente, além de reduzir a quantidade de cálculos envolvidos.
As convoluções 1x1 foram introduzidas para melhorar a eficiência computacional e a flexibilidade das redes neurais convolucionais, especialmente em arquiteturas como a Inception. Embora inicialmente possam parecer triviais, as convoluções 1x1 têm um papel crucial em reduzir a dimensionalidade dos dados sem perder informações relevantes. Ao aplicar um filtro 1x1, a convolução é realizada apenas sobre a profundidade (ou canais) da entrada, sem afetar a largura ou altura da imagem. Isso permite a fusão de informações de diferentes canais, o que facilita a combinação de características complexas de forma eficiente. Além disso, essa técnica reduz o número de parâmetros e operações, resultando em uma rede mais leve e rápida, o que foi fundamental para o sucesso de redes profundas como a GoogLeNet/Inception (Szegedy et al, 2014) e ResNet (He et al, 2016).
Conexões Residuais#
As conexões residuais foram a principal inovação da ResNet (He et al, 2016) e representam um avanço crucial no design de redes neurais profundas. Elas introduzem um atalho que permite que o sinal original da entrada seja passado diretamente para uma camada posterior, sem passar pelas camadas intermediárias, criando o que é chamado de mapeamento de identidade. Esse conceito resolve o problema do gradiente desvanecente, que dificultava o treinamento de redes muito profundas, ao garantir que os gradientes possam fluir de forma mais eficaz para as camadas anteriores. As conexões residuais permitem que a rede aprenda diferenças residuais em vez de tentar ajustar o mapeamento completo da função, o que facilita o aprendizado. Como resultado, redes muito profundas, como as versões da ResNet com 50, 101 ou até 152 camadas, podem ser treinadas de maneira eficaz, sem degradação de desempenho, permitindo que elas capturem representações complexas dos dados.

Aplicações de Redes Neurais Convolucionais#
Embora as CNNs sejam amplamente conhecidas por suas aplicações em visão computacional, elas também têm sido adaptadas para lidar com séries temporais e outros tipos de dados não visuais. Em séries temporais, as CNNs podem capturar padrões locais ao longo do tempo, assim como capturam padrões espaciais em imagens, aplicando convoluções para detectar tendências, sazonalidades ou eventos relevantes em sequências temporais. Por exemplo, CNNs são usadas em previsões financeiras, onde conseguem identificar padrões em dados históricos de preços, ou em análise de sinais biomédicos, como ECGs, para detectar anomalias de saúde. Além disso, CNNs têm sido aplicadas a dados textuais para tarefas de classificação de texto e análise de sentimentos, onde as convoluções identificam sequências de palavras ou frases relevantes. Ao lidar com dados sequenciais, as CNNs competem com RNNs e Transformers, mostrando que são versáteis e eficazes em diversos tipos de dados, além de imagens.
Exemplo#
No seguinte exemplo, vamos desenvolver uma rede MLP simples e uma LetNet-5 para o famoso problema MNIST, de reconhecimento de dígitos.
import seaborn as sns
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
from sklearn.metrics import f1_score, confusion_matrix
# Transformações dos dados
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Carregar o dataset MNIST
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=1000, shuffle=False)
100%|██████████| 9.91M/9.91M [00:00<00:00, 133MB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 29.5MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 106MB/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 6.63MB/s]
i = 101
plt.imshow(trainset[i][0][0])
plt.title(f'Amostra {i} - Classe {trainset[i][1]}')
plt.show()
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 28px X 28px
self.fc2 = nn.Linear(128, 10) # Saída de 10 classes para o MNIST
def forward(self, x):
x = x.view(-1, 28*28) # Flatten
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Instanciar a rede, a função de perda e o otimizador
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Treinamento
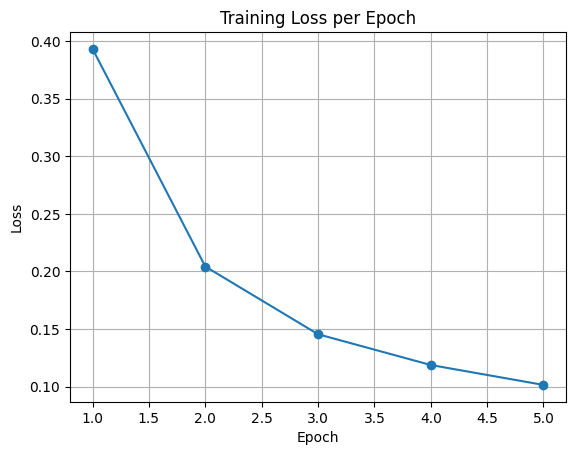
epochs = 5
epoch_losses = []
for epoch in range(epochs):
running_loss = 0.0
progress_bar = tqdm(trainloader, desc=f"Epoch {epoch+1}/{epochs}", leave=False)
for inputs, labels in progress_bar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
progress_bar.set_postfix(loss=loss.item())
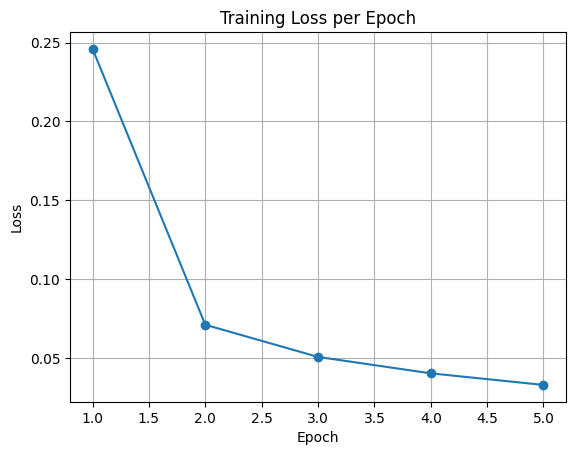
avg_loss = running_loss / len(trainloader)
epoch_losses.append(avg_loss)
# Plot training loss per epoch
plt.figure()
plt.plot(range(1, epochs+1), epoch_losses, marker='o')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss per Epoch")
plt.grid(True)
plt.show()
# Avaliação no conjunto de teste
model.eval()
y_true = []
y_pred = []
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
# Accuracy
accuracy = (np.array(y_true) == np.array(y_pred)).mean() * 100
print(f'Accuracy on test set: {accuracy:.2f}%')
# F1-macro score only
f1_macro = f1_score(y_true, y_pred, average='macro')
print(f'F1 Macro: {f1_macro:.4f}')
# Confusion Matrix
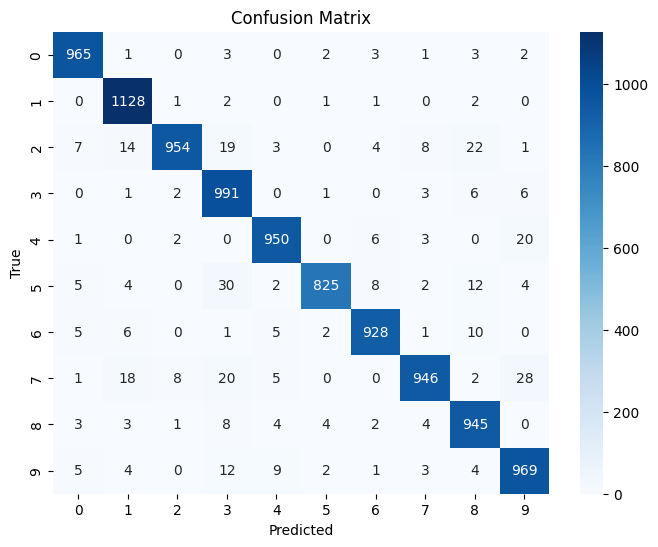
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.title("Confusion Matrix")
plt.show()
Accuracy on test set: 96.01%
F1 Macro: 0.9600
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # MNIST tem 1 canal de entrada
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.fc1 = nn.Linear(16 * 4 * 4, 120) # As dimensões após o conv2 dependem do tamanho da entrada
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # Saída de 10 classes para o MNIST
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, kernel_size=2, stride=2)
x = x.view(-1, 16 * 4 * 4) # Flatten
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# Instanciar a rede, a função de perda e o otimizador
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LeNet5().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Treinamento
epochs = 5
epoch_losses = []
for epoch in range(epochs):
running_loss = 0.0
progress_bar = tqdm(trainloader, desc=f"Epoch {epoch+1}/{epochs}", leave=False)
for inputs, labels in progress_bar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
progress_bar.set_postfix(loss=loss.item())
avg_loss = running_loss / len(trainloader)
epoch_losses.append(avg_loss)
# Plot training loss per epoch
plt.figure()
plt.plot(range(1, epochs+1), epoch_losses, marker='o')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss per Epoch")
plt.grid(True)
plt.show()
# Avaliação no conjunto de teste
model.eval()
y_true = []
y_pred = []
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
# Accuracy
accuracy = (np.array(y_true) == np.array(y_pred)).mean() * 100
print(f'Accuracy on test set: {accuracy:.2f}%')
# F1-macro score only
f1_macro = f1_score(y_true, y_pred, average='macro')
print(f'F1 Macro: {f1_macro:.4f}')
# Confusion Matrix
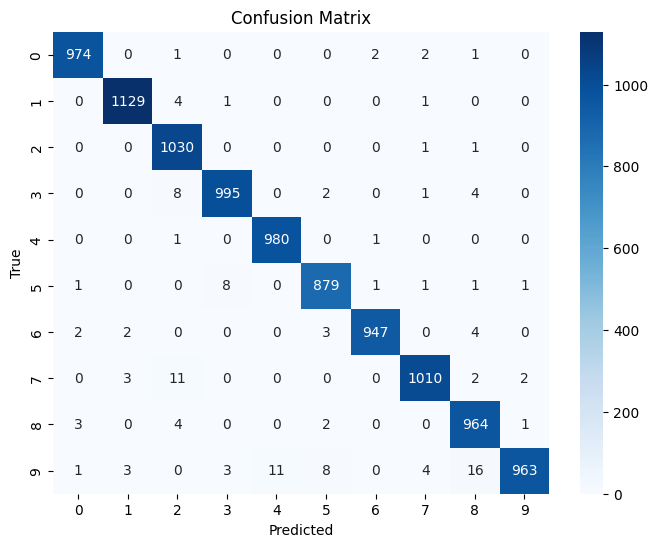
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.title("Confusion Matrix")
plt.show()
Accuracy on test set: 98.71%
F1 Macro: 0.9870
Considerações Finais#
Neste capítulo, falamos sobre redes neurais convolucionais e seus principais componentes.
Próximos capítulos#
Nos próximos capítulos, falaremos sobre arquiteturas especializadas em modelagem de sequencias, como séries temporais e texto, utilizando redes neurais recorrentes e transformers.
Exercícios#
Dobre a largura da LeNet-5.
Dobre a profundidade da LeNet-5.
Apresente o resultado das novas arquiteturas e discuta sobre (número de parâmetros, profundidade e acurácia).
Referências#
Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural networks, 2(5), 359-366.
Alwosheel, A., Van Cranenburgh, S., & Chorus, C. G. (2018). Is your dataset big enough? Sample size requirements when using artificial neural networks for discrete choice analysis. Journal of choice modelling, 28, 167-182.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) (pp. 807-814).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
Ioffe, S. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.