
Joint-embedding Learning¶
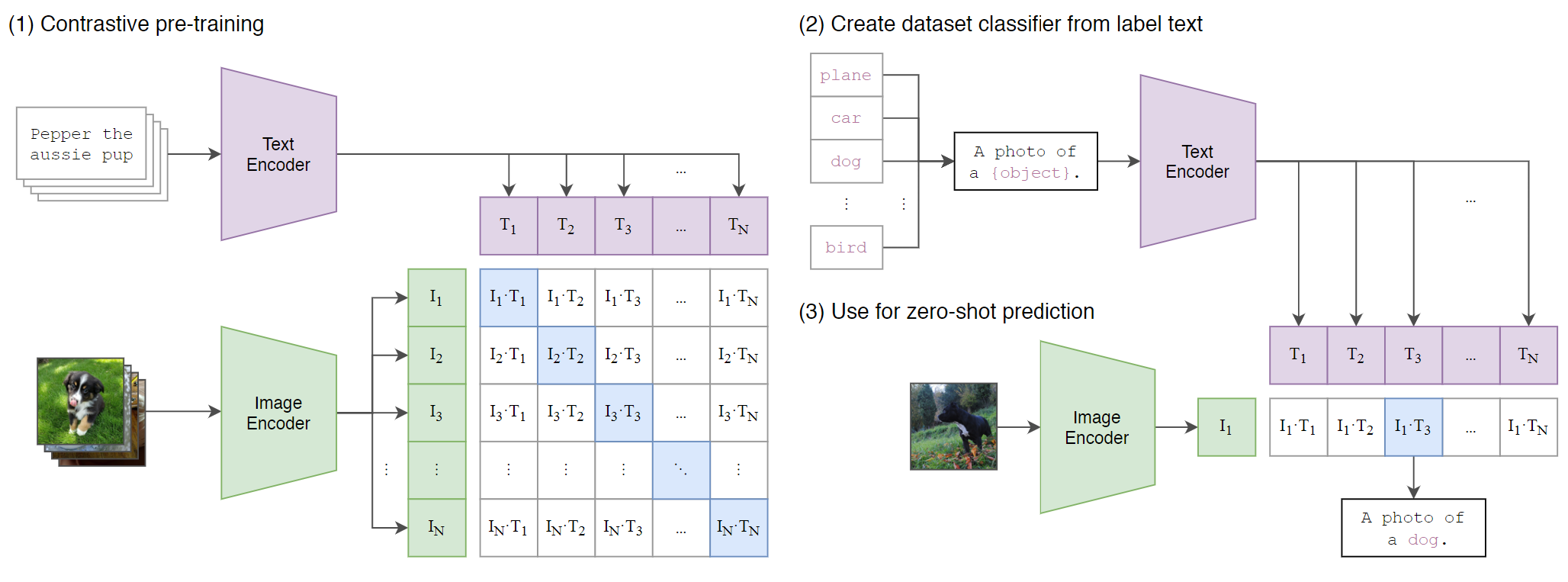
O joint-embedding learning é uma abordagem que busca projetar diferentes modalidades de dados, como texto e imagens, em um espaço de representação compartilhado. O objetivo é permitir que dados de diferentes tipos sejam comparáveis diretamente, mesmo que venham de modalidades distintas. Esse processo de aprendizado é amplamente utilizado em modelos como o CLIP (Contrastive Language-Image Pre-training), que mapeia texto e imagens para o mesmo espaço vetorial, permitindo que descrições textuais e imagens correspondentes fiquem próximas entre si nesse espaço (Ramesh et al., 2022). Essa técnica possibilita tarefas como a busca cruzada entre modalidades, onde, por exemplo, pode-se encontrar uma imagem a partir de uma descrição textual ou vice-versa. Outra aplicação de joint-embedding é a criação de espaços semânticos que facilitam o zero-shot learning, permitindo que o modelo generalize para tarefas ou classes não vistas durante o treinamento. A principal vantagem do joint-embedding learning é a criação de uma representação comum que captura as relações semânticas entre diferentes formas de dados, tornando o aprendizado multimodal mais eficiente e flexível.
Formas¶
Existem diferentes tipos de joint-embedding que variam conforme a forma como as representações de diferentes modalidades são combinadas no espaço compartilhado. Um dos tipos mais comuns é o joint-embedding contrastivo, utilizado em modelos como o CLIP, onde as representações de modalidades (como imagens e textos) são aprendidas em paralelo e forçadas a se alinhar no mesmo espaço por meio de loss functions contrastivas. Esse método garante que as representações de itens correspondentes, como uma imagem e sua legenda, estejam próximas no espaço de embedding, enquanto itens não relacionados ficam distantes.
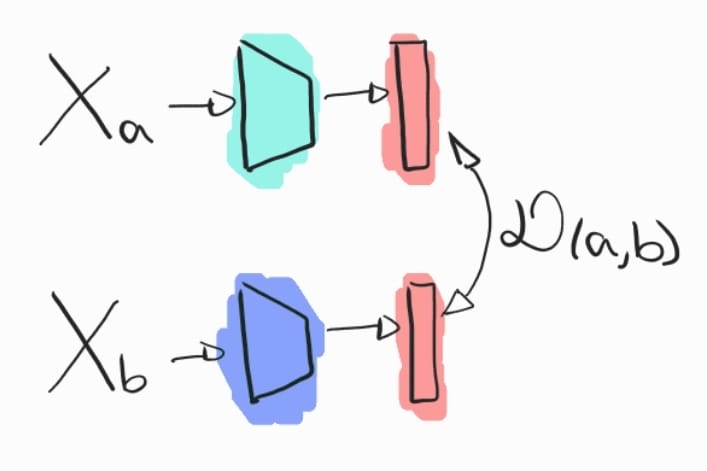
Outro tipo é o joint-embedding supervisionado, onde as modalidades são projetadas para um espaço compartilhado usando rótulos explícitos durante o treinamento, ajudando o modelo a aprender uma correspondência entre modalidades supervisionada por dados rotulados.
Há também o joint-embedding não supervisionado, onde o modelo aprende a alinhar diferentes modalidades de forma autônoma, sem depender de rótulos, explorando padrões intrínsecos nos dados.
Esses diferentes tipos de joint-embedding são amplamente aplicados em tarefas como busca multimodal, classificação cross-modal, e zero-shot learning, em que a flexibilidade do modelo para integrar informações de diferentes modalidades no mesmo espaço é crítica para seu sucesso.
Referências¶
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2), 3.