
Multi-modal Learning¶
O multi-modal learning é um paradigma de aprendizado que envolve a integração de dados de diferentes modalidades, como imagens, texto, áudio e vídeo, em um único modelo. A ideia principal é aproveitar as informações complementares oferecidas por cada modalidade para melhorar o desempenho em tarefas complexas. Por exemplo, um modelo de aprendizado multimodal pode combinar dados visuais e linguísticos para gerar descrições de imagens ou responder a perguntas sobre o conteúdo visual. Uma das grandes vantagens do multi-modal learning é sua capacidade de capturar representações mais ricas e contextualmente completas, o que resulta em uma melhor generalização. Essa abordagem tem aplicações em áreas como reconhecimento de fala, geração de legendas para imagens, e sistemas de recomendação, onde a combinação de várias fontes de dados permite que o modelo ofereça soluções mais precisas e robustas.
Entradas Multi-modais¶
Os modelos com entradas multi-modais são aqueles que processam simultaneamente diferentes tipos de dados, como imagens, texto e áudio, para realizar uma ou mais tarefas. A principal vantagem desses modelos é a capacidade de combinar as informações complementares fornecidas por cada modalidade, permitindo que o modelo tenha uma visão mais abrangente e rica do problema. Por exemplo, em tarefas de pergunta-resposta visual (Visual Question Answering - VQA), o modelo recebe tanto uma imagem quanto uma pergunta em formato textual e precisa gerar uma resposta precisa, utilizando dados visuais e linguísticos. Outro exemplo são os sistemas de recomendação multimodal, que integram dados como histórico de comportamento, imagens de produtos e descrições textuais para fornecer recomendações mais personalizadas. Esses modelos são amplamente usados em várias áreas, como saúde, onde combinam imagens médicas e relatórios clínicos, e em sistemas autônomos, que processam dados de sensores visuais e LiDAR. O uso de entradas multi-modais permite que o modelo capture relações mais profundas entre os dados e ofereça soluções mais robustas e adaptáveis.
Formas¶
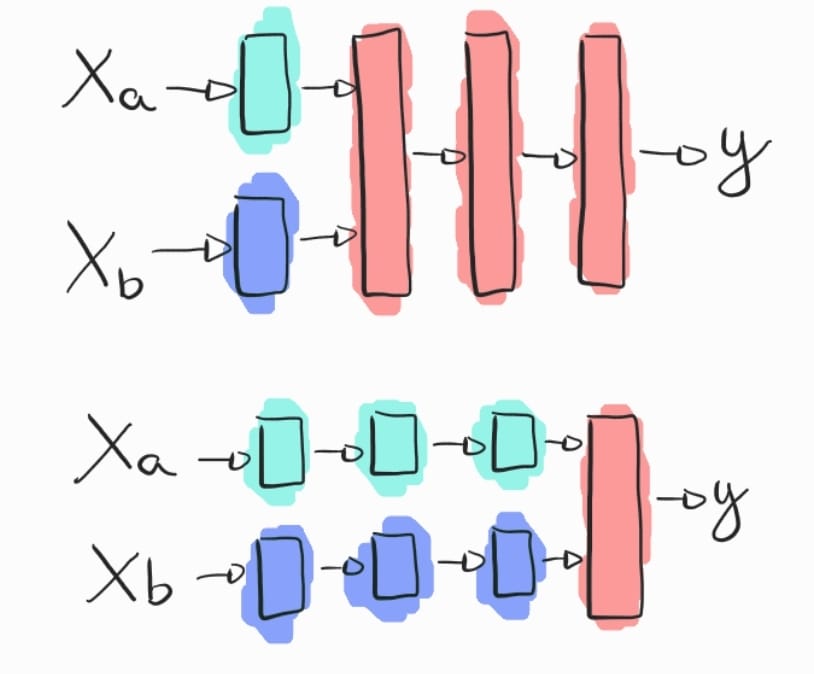
Os dados multi-modais podem ser processados de diferentes maneiras, dependendo do estágio em que as informações de cada modalidade são combinadas no modelo. Uma abordagem comum é a fusão antecipada (early fusion), onde as entradas de diferentes modalidades são combinadas logo no início do pipeline, criando uma representação conjunta que é alimentada pelas camadas subsequentes da rede neural. Outra abordagem é a fusão tardia (late fusion), onde cada modalidade é processada separadamente por redes dedicadas, e as representações resultantes são combinadas apenas nas etapas finais para gerar a predição. Há também a fusão híbrida (hybrid fusion), onde as modalidades são combinadas em diferentes estágios do modelo, permitindo que cada fonte de dados contribua de forma mais eficaz em diferentes níveis de abstração. Essas técnicas são utilizadas em tarefas como reconhecimento de fala multimodal, sistemas de recomendação e análise de vídeos, onde a combinação eficiente de diferentes modalidades pode melhorar a precisão e robustez dos modelos. Cada abordagem de fusão oferece um equilíbrio entre complexidade computacional e a capacidade de capturar relações profundas entre as modalidades.
Modelos para Conversão¶
Os modelos multi-modais para conversão de dados são projetados para transformar dados de uma modalidade em outra, aproveitando informações provenientes de fontes distintas. Um exemplo notável é o DALL-E, que converte texto em imagens, gerando representações visuais a partir de descrições textuais detalhadas. Outro exemplo é o Text-to-Speech (TTS), onde o modelo transforma texto em áudio, permitindo que assistentes virtuais, como Alexa e Google Assistant, conversem com os usuários em linguagem natural.
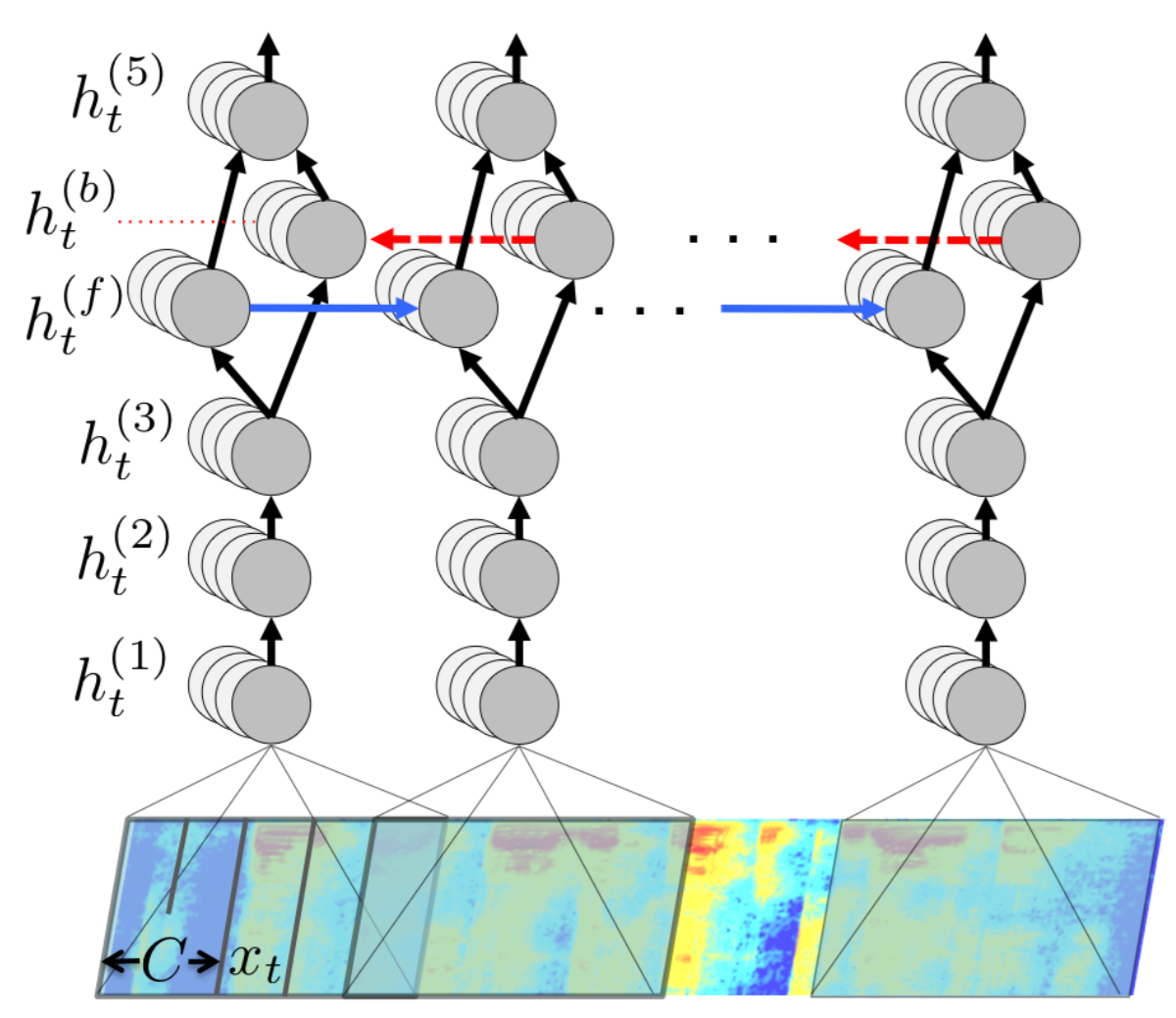
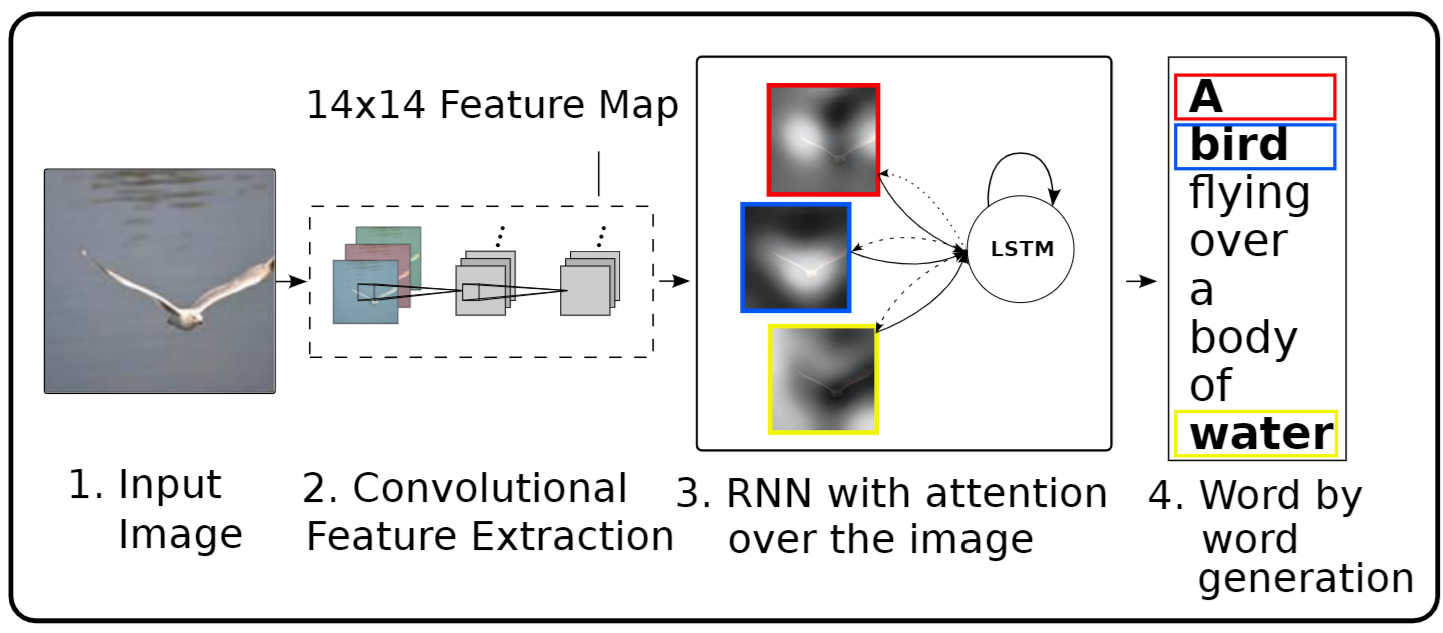
Da mesma forma, sistemas de Speech-to-Text (STT) convertem áudio em texto (Hannun, 2014), sendo amplamente usados em reconhecimento de fala para transcrição de áudio. Também temos exemplos de conversão de imagens em legendas (Xu, 2015). Esses modelos de conversão entre modalidades são essenciais para facilitar a comunicação entre humanos e máquinas, criar conteúdos automaticamente, e melhorar a acessibilidade para deficientes auditivos ou visuais.
Saídas e Entradas Multi-modais¶
Perceiver e Perceiver IO (2021)¶
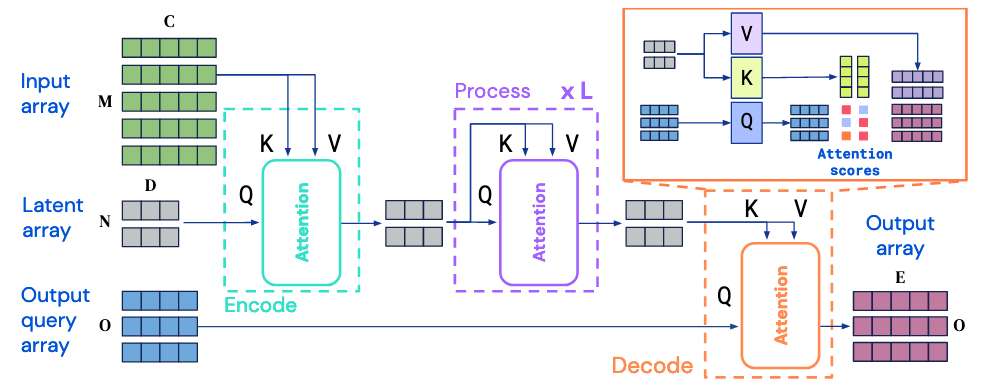
O Perceiver foi desenvolvido para enfrentar as limitações de escalabilidade dos Transformers tradicionais, especialmente quando aplicados a entradas de alta dimensão, como vídeos ou nuvens de pontos 3D. Ao invés de processar todos os tokens de entrada diretamente, o Perceiver projeta os dados para um espaço latente de dimensão fixa, onde o mecanismo de atenção latente é aplicado, reduzindo drasticamente o custo computacional. Uma extensão, o Perceiver IO, vai além ao adaptar esse modelo para lidar com uma variedade de tipos de entradas e saídas, permitindo que o mesmo modelo processe dados como imagens, vídeos, texto e até sinais 3D, com diferentes formatos de saída. Com essa flexibilidade e eficiência, o Perceiver e o Perceiver IO estão tornando os Transformers mais adequados para aplicações multimodais e de grandes dimensões.
Aplicações¶
As aplicações de multi-modal learning são amplas e abrangem diversas áreas que se beneficiam da combinação de diferentes tipos de dados. Na área de visão computacional, por exemplo, sistemas como Visual Question Answering (VQA) integram imagens e textos para responder perguntas sobre o conteúdo visual de uma cena. Outra aplicação comum é na geração de legendas automáticas para imagens e vídeos, onde modelos multimodais combinam informações visuais e linguísticas para gerar descrições em linguagem natural. No campo da saúde, modelos multimodais podem combinar imagens médicas (como raios-X) com dados clínicos (como relatórios de pacientes) para realizar diagnósticos mais precisos e eficientes. Sistemas de recomendação multimodal também utilizam uma combinação de dados de texto, imagem e vídeo para personalizar recomendações de produtos em plataformas de e-commerce e mídia social. Além disso, os assistentes virtuais, como os sistemas de reconhecimento de fala, integram dados de áudio e texto para entender e gerar respostas mais naturais. Essas aplicações demonstram como a integração de múltiplas modalidades permite que os modelos compreendam melhor contextos complexos e forneçam soluções mais robustas.
Referências¶
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., ... & Sutskever, I. (2021, July). Zero-shot text-to-image generation. In International conference on machine learning (pp. 8821-8831). Pmlr.
Hannun, A. (2014). Deep Speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567.
Xu, K. (2015). Show, attend and tell: Neural image caption generation with visual attention. arXiv preprint arXiv:1502.03044.
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., & Carreira, J. (2021, July). Perceiver: General perception with iterative attention. In International conference on machine learning (pp. 4651-4664). PMLR.
Jaegle, A., Borgeaud, S., Alayrac, J. B., Doersch, C., Ionescu, C., Ding, D., ... & Carreira, J. (2021). Perceiver io: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795.