
Redução de Modelos¶
A redução de modelos, ou model compression, é uma técnica utilizada para otimizar redes neurais, diminuindo seu tamanho e complexidade sem sacrificar significativamente o desempenho. Métodos como pruning, quantização e knowledge distillation são comumente empregados para reduzir a quantidade de parâmetros e operações no modelo, tornando-o mais eficiente em termos de armazenamento e tempo de inferência. Pruning remove conexões ou neurônios irrelevantes, enquanto a quantização reduz a precisão dos números utilizados, como passando de 32 bits para 8 bits, para diminuir o uso de memória. Já o knowledge distillation envolve treinar um modelo menor (aluno) a partir das previsões de um modelo maior (professor), transferindo seu conhecimento de maneira compacta. Essas técnicas são particularmente valiosas para a implementação de redes neurais em dispositivos com recursos limitados, como celulares ou sistemas embarcados.
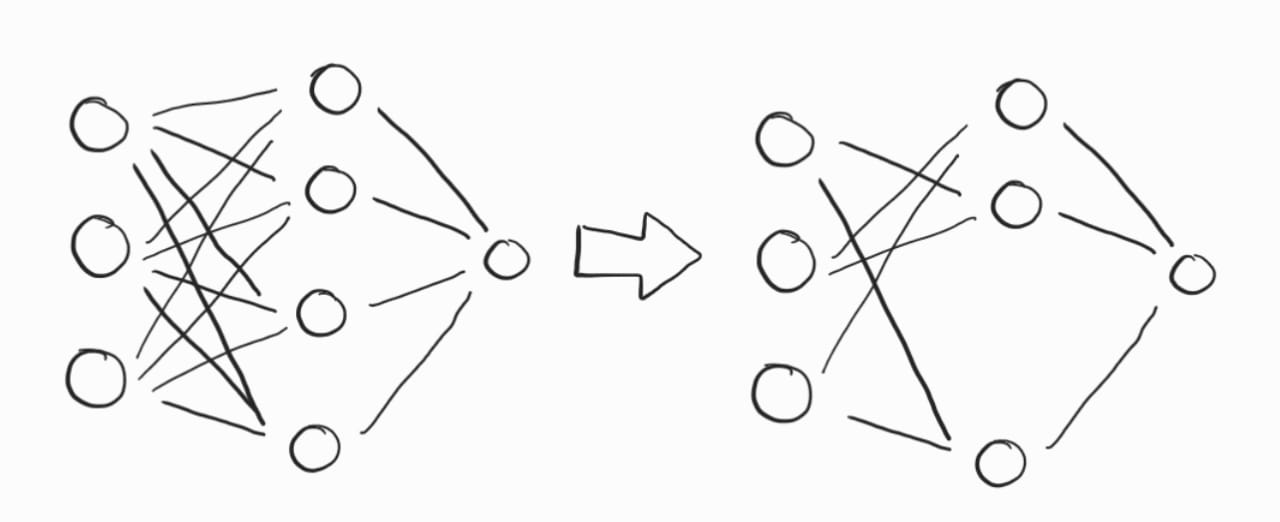
Prunning¶
O conceito de pruning em redes neurais foi introduzido pela primeira vez no paper “Optimal Brain Damage” (LeCun et al., 1990). Neste trabalho seminal, os autores propuseram uma técnica para reduzir a complexidade de redes neurais removendo pesos que tivessem pouca influência sobre o desempenho geral do modelo. A abordagem se baseava na ideia de eliminar conexões irrelevantes ou com pequena contribuição para a função de perda, visando simplificar a rede sem comprometer significativamente sua precisão. Esse trabalho abriu caminho para uma série de técnicas de pruning que se tornaram fundamentais para a compressão de modelos e o desenvolvimento de redes neurais mais eficientes.
Quantization¶
A quantization é uma técnica essencial na computação de deep learning que busca reduzir a precisão numérica dos parâmetros de uma rede neural, como pesos e ativações, para representações de menor bit-depth, como 8-bit, sem comprometer significativamente o desempenho do modelo. Ela permite a execução mais eficiente em termos de memória e poder de processamento, sendo amplamente aplicada em dispositivos de borda e inferência em tempo real. Um paper seminal nessa área é “Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper” (Jacob et al., 2018), que explora a quantização de redes profundas com foco em eficiência computacional.
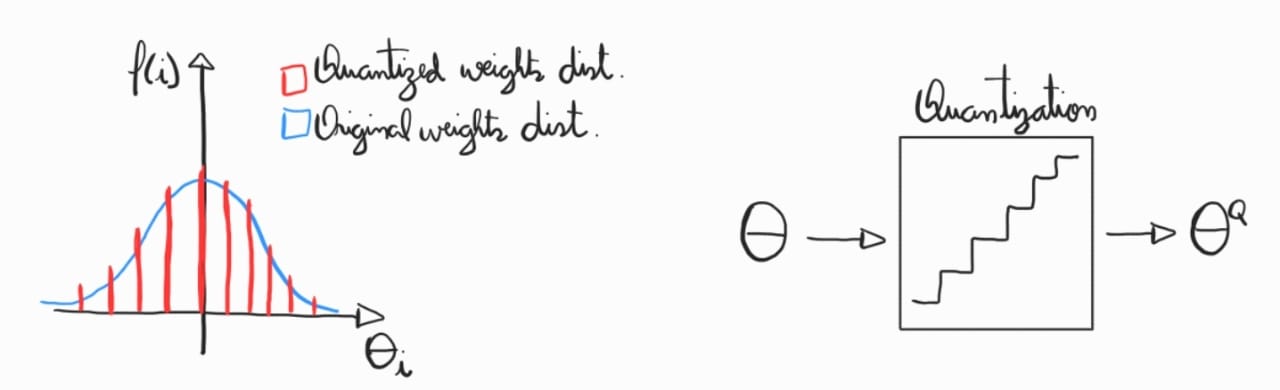
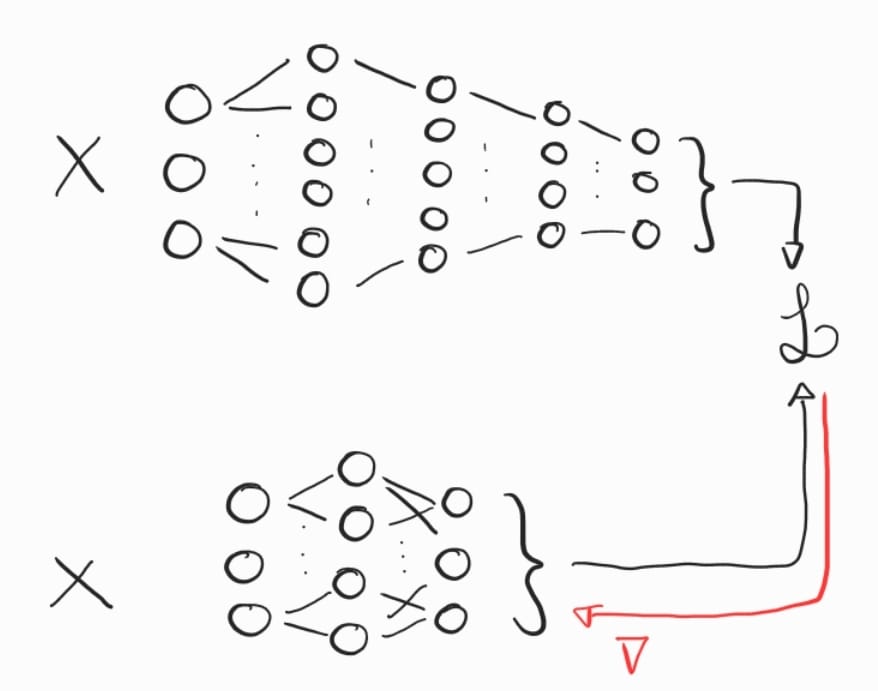
Model Distillation¶
Model distillation é uma técnica em aprendizado de máquina utilizada para transferir o conhecimento de um modelo grande e complexo, geralmente chamado de teacher model, para um modelo menor e mais eficiente, conhecido como student model. A ideia central é que o modelo grande pode capturar padrões mais sutis nos dados, e o modelo menor aprende a replicar esse comportamento ao ser treinado para imitar as saídas ou as distribuições de probabilidade produzidas pelo modelo maior. Isso é útil para reduzir a complexidade computacional e o tamanho dos modelos, tornando-os mais adequados para execução em dispositivos com recursos limitados, sem perder muita precisão. O trabalho seminal na área é “Distilling the Knowledge in a Neural Network” (Hinton et al., 2015), que introduz a técnica e explora como o student model pode alcançar desempenho comparável ao teacher model com uma arquitetura mais compacta.
Low-order Rank Adaptation (LoRA)¶
TODO
Referências¶
LeCun, Y., Denker, J., & Solla, S. (1989). Optimal brain damage. Advances in neural information processing systems, 2.
Krishnamoorthi, R. (2018). Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342.
Hinton, G. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.