
Paradigmas de Aprendizagem com Dados Limitados¶
Os paradigmas de aprendizagem com dados limitados são fundamentais para lidar com a escassez de dados rotulados. O transfer learning permite que modelos pré-treinados em grandes conjuntos de dados sejam adaptados a novas tarefas com menos dados, enquanto o few-shot learning utiliza poucas amostras para treinar modelos que conseguem generalizar bem. Já o zero-shot learning possibilita que modelos reconheçam classes inéditas sem amostras diretas, baseando-se em descrições ou relações semânticas. Essas abordagens otimizam o uso de dados reduzidos, acelerando o aprendizado e melhorando a adaptação dos modelos.
Transfer Learning¶
Transfer learning é uma técnica poderosa em redes neurais que permite reutilizar o conhecimento adquirido por um modelo pré-treinado em uma tarefa de origem para resolver uma tarefa diferente, geralmente com menos dados disponíveis. Ao invés de treinar um modelo do zero, o transfer learning aproveita as camadas iniciais de um modelo, que capturam características genéricas dos dados, e ajusta as camadas finais para a nova tarefa. Isso resulta em uma aceleração do processo de treinamento e, frequentemente, em uma melhoria no desempenho, especialmente em cenários onde o volume de dados rotulados é limitado. É amplamente utilizado em áreas como visão computacional e processamento de linguagem natural, onde redes pré-treinadas em grandes bases de dados podem ser adaptadas para aplicações mais específicas e especializadas.
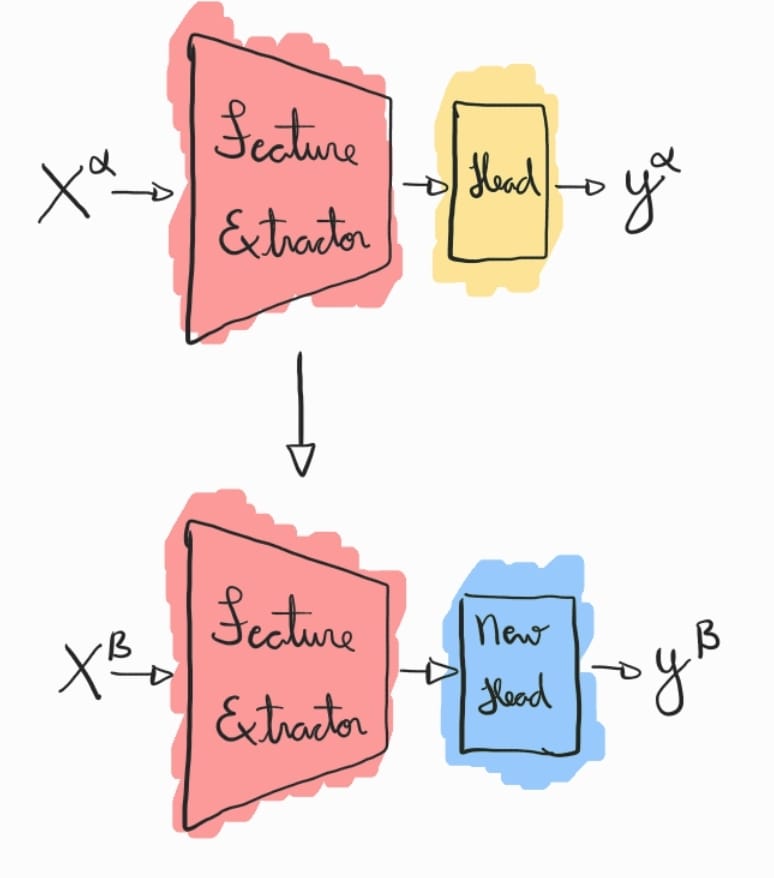
O transfer learning teve aplicações pioneiras em diferentes áreas, começando com aprendizado por reforço nos anos 90, onde Lorien Pratt introduziu a ideia de transferência entre tarefas relacionadas. No processamento de linguagem natural, o word2vec (2013) trouxe uma abordagem importante ao pré-treinar representações de palavras que podiam ser adaptadas a diferentes tarefas linguísticas. Já em visão computacional, o AlexNet (2012) marcou um grande avanço ao ser pré-treinado no ImageNet e posteriormente refinado para resolver problemas específicos com menos dados, consolidando o uso de transfer learning em redes neurais profundas.
Few-shot Learning¶
Few-shot learning é uma abordagem de aprendizado que permite que modelos generalizem bem a partir de um número extremamente reduzido de amostras de treinamento (Li et al., 2016). Em vez de depender de grandes volumes de dados, como na aprendizagem tradicional, o few-shot learning utiliza técnicas avançadas, como redes siamesas e prototípicas, para aprender a diferença entre classes a partir de poucos exemplos. O objetivo é ensinar o modelo a identificar padrões e características gerais que possam ser aplicados a novas amostras com pouca informação. Essa técnica tem sido especialmente útil em áreas como reconhecimento de imagens, onde rotular grandes quantidades de dados é caro ou inviável.
Zero-shot Learning¶
O primeiro trabalho marcante sobre zero-shot learning foi “Zero-Shot Learning with Semantic Output Codes” (Palatucci et al.) publicado em 2009. Neste estudo, os autores apresentaram uma abordagem para reconhecimento de objetos em categorias para as quais o modelo não tinha exemplos diretos durante o treinamento. O método utiliza descrições semânticas das classes conhecidas para fazer inferências sobre novas classes, permitindo que o modelo reconheça objetos sem ter visto exemplos específicos dessas classes anteriormente. Esse trabalho introduziu o conceito de zero-shot learning ao explorar como características semânticas podem ser utilizadas para generalizar além das classes rotuladas, marcando o início de uma nova linha de pesquisa em aprendizagem de máquina.
Referências¶
Pratt, L. Y., Mostow, J., & Kamm, C. A. (1991, July). Direct transfer of learned information among neural networks. In Proceedings of the ninth National conference on Artificial intelligence-Volume 2 (pp. 584-589).
Mikolov, T. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Fei-Fei, L., Fergus, R., & Perona, P. (2006). One-shot learning of object categories. IEEE transactions on pattern analysis and machine intelligence, 28(4), 594-611.
Palatucci, M., Pomerleau, D., Hinton, G. E., & Mitchell, T. M. (2009). Zero-shot learning with semantic output codes. Advances in neural information processing systems, 22.